Kešatmiņas aizvietošanas algoritmi: LRU, LFU, ARC un citi
Iepazīstiet kešatmiņas aizvietošanas algoritmus (LRU, LFU, ARC u.c.): salīdzinājums, darbības principi, priekšrocības un praktiski padomi trāpījumu biežuma un latentuma optimizēšanai.
Kešatmiņas algoritms ir algoritms, ko izmanto kešatmiņas vai datu grupas pārvaldībai. Tā pamatuzdevums — ja kešatmiņa ir pilna un parādās jauns vienums, izlemt, kurš esošais vienums jāizmet, lai atbrīvotu vietu. Divi svarīgi rādītāji ir hit rate (trāpījumu biežums) — cik bieži pieprasījumi tiek apkalpoti no kešatmiņas, un termins latence — cik ātri var saņemt kešatmiņā esošu elementu. Kešatmiņas aizvietošanas algoritmi parasti cenšas līdzsvarot trāpījumu skaitu (veiktspēju) un kavēšanos (latenci), kā arī implementācijas izmaksas un atmiņas patēriņu.
Attēlu galerija
7 Attēli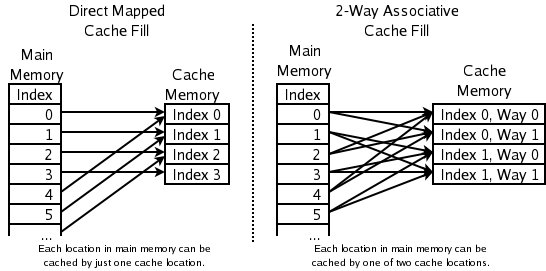



Optimālais (ideālais) algoritms
Teorētiski visefektīvākais kešēšanas algoritms būtu tas, kas vienmēr izmet to informāciju, kas nebūs nepieciešama visilgāk nākotnē. Šo optimālo rezultātu dēvē par Beladija optimālo algoritmu jeb gaišreģa algoritmu. Tas dod zemāko iespējamo kešatmiņas kļūdu skaitu noteiktā pieprasījumu secībā, bet praksē to nevar realizēt, jo ir jāzina precīza nākotnes pieprasījumu secība. Optimālo rezultātu var aprēķināt tikai retrospektīvi, pēc eksperimenta, un tas tiek izmantots kā salīdzināšanas standarts: praktiskos risinājumos mērķis ir pietuvoties šim optimumam.
Biežāk izmantotie algoritmi un to īss apraksts
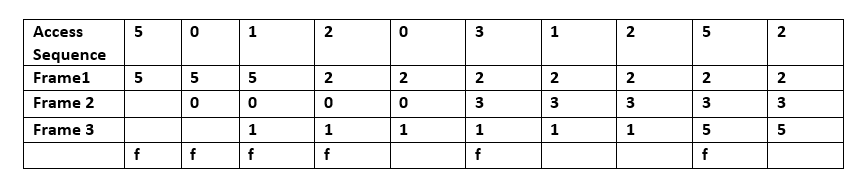
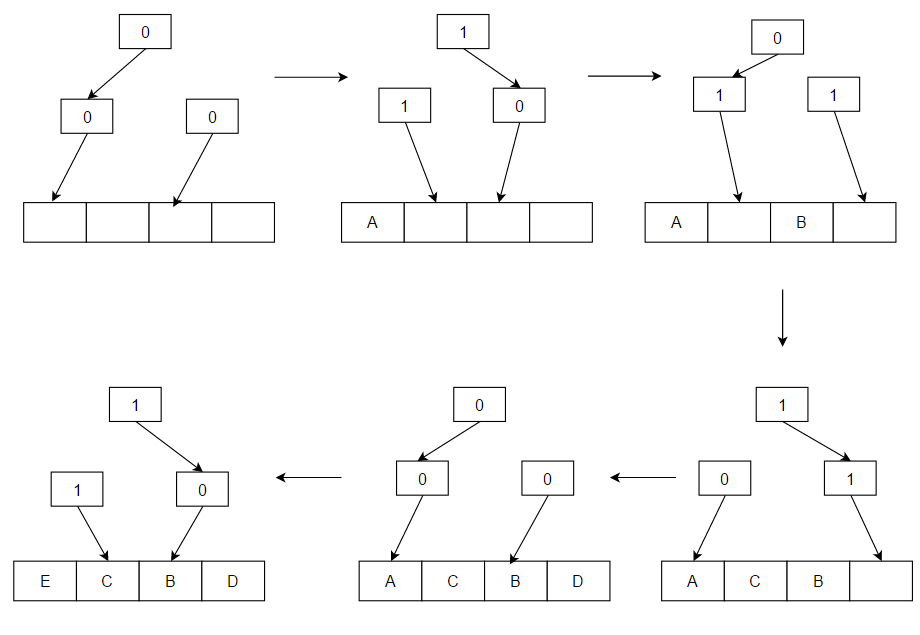
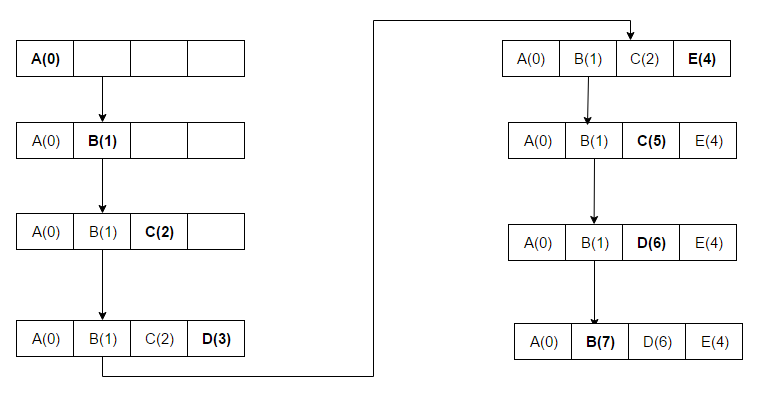
- Vismazāk pēdējā laikā izmantotie (LRU): izmet vienumu, kas visilgāko laiku nav ticis izmantots. LRU prasa sekot pēdējiem izmantošanas laikiem — to var īstenot ar dubultsaistītu sarakstu un hašu tabulu, kur piekļuve pārvieto elementu uz saraksta priekšpusi (O(1) operācijas). Pastāv arī daudzas LRU variācijas un uzlabojumi, un LRU ir kešatmiņas algoritmu saime, kurā ietilpst tādi risinājumi kā 2Q (Theodore Johnson un Dennis Shasha) un LRU/K (Pat O'Neil, Betty O'Neil un Gerhard Weikum). LRU labi darbojas, ja pieprasījumu secība rāda lokālu atkārtošanos, bet var būt nepiemērots, ja ir lieli secīgi skenēšanas darbi (capacity thrashing).
- Pēdējo reizi izmantots (MRU): izmet nesenāk izmantotu vienumu. MRU reizēm lieto specifiskos scenārijos, piemēram, ja bieži tiek lasītas jaunas datu rindas, bet reti atkārtoti — dažās datubāzu kešatmiņās tas var būt labāks risinājums nekā LRU (datubāzes).
- Pseido-LRU (PLRU): aproksimācija LRU, kas prasa mazāk metadatu (piem., viens bits uz elementu vai koks ar bitiem), tāpēc to izmanto sistēmās, kur pilns LRU ir pārāk dārgs. PLRU nenodrošina precīzu LRU uzvedību, bet parasti izmet vienu no vismazāk izmantojamajiem elementiem.
- 2-virzienu asociatīvais komplekts (2-way set-associative): izstrādājot kešatmiņu ātrdarbīgām procesoru līnijām, jaunā elementa adrese nosaka vienu no divām vietām konkrētā komplektā; no tām izmet LRU. Prasībās ir viens bits uz katru pāri, kas norāda, kura no divām līnijām bija vecāka/mazāk izmantota.
- Tiešā kartētā kešatmiņa (direct-mapped): katrai adresei ir precīzi viena vieta kešatmiņā — visvienkāršākā un ātrākā shēma, taču tā var radīt lielu sadursmju skaitu (conflict misses) noteiktos pieprasījumu veidos.
- Visretāk izmantotie (LFU): katram vienumam saglabā skaitītāju ar piekļuves biežumu; izmet to, kam ir vismazākais skaitītājs. LFU labi strādā, ja populāri vienumi ir ilgstoši piesaistoši, taču slikti reaģē uz īslaicīgām pieprasījumu "glāstiem" (one-off spikes) — vienums ar vienu īsu periodu var palikt kešā pārāk ilgi. Lai uzlabotu, izmanto nolietojuma (aging) mehānismus, kas pakāpeniski samazina skaitītājus.
- Adaptīvā aizvietošanas kešatmiņa (ARC): Adaptive Replacement Cache — adaptīvi balansē starp LRU un LFU tipu uzvedību, uzturot vairākas sarakstu struktūras un pielāgojot parametru pusi atkarībā no pieprasījumu rakstura. ARC bieži sniedz labāku rezultātu nekā tīri LRU vai LFU stratēģijas reālos darba slodzēs.
- 2Q: 2_Kārtu (2-Queue) mehānisms, kas atdala īslaicīgos “pirms” pieprasījumus no reizēm atkārtotiem — apvieno izejošo virsmu un bieži pieprasīto segmentu, līdz ar to novērš īslaicīgu “karstā” datu nonākšanu ilgtermiņa kešā.
- MQ (Multi-Queue): vairākrindu (multi-queue) pieeja (piem., Zhou, J.F., Philbin un Kai Li), kur objektus klasificē pēc to biežuma un pārvieto starp rindām, ļaujot labāk atšķirt īslaicīgas un pastāvīgas popularitātes tendences.
- LIRS (Low Inter-reference Recency Set): modernāka LRU/LFU hibrīdmetode, kas izmanto “stack distance” koncepciju, lai labāk atpazītu objektus ar zemu intervālu starp piekļuvēm; bieži dod labāku rezultātu nekā pamata LRU.
- CLOCK: efektīva LRU aproksimācija izmantojot "use" bitus un riņķveida bufera indeksu ("sviru"). CLOCK ir populāra operētājsistēmu lapu aizvietošanā, jo prasa mazus metadatus un ātras operācijas.
- CAR (CLOCK with Adaptive Replacement): apvieno CLOCK ātrumu ar adaptīvu ARC principu, lai tiktu galā ar dažādām darba slodzēm.
Praktiskie aspekti un implementācija
- Laika un atmiņas sarežģītība: pilns LRU ar dubultsaistītu sarakstu un hašu tabulu — O(1) piekļuve un O(1) ievietošanas/izņemšanas izmaksas, bet papildu atmiņas izmaksas katram elementam (rādītāji). PLRU, CLOCK un tiešā kartēšana samazina metadatus uz elementu.
- Metadatu izmaksas: atkarībā no sistēmas (CPU kešatmiņas pret datu bāzes kešiem) metadati (bitu skaits, skaitītāji, saraksti) var būt būtiski — tas ietekmē izvēli starp precīzu LRU un tā aproksimācijām.
- Darba slodzes raksturs: algoritma piemērotība lielā mērā atkarīga no pieprasījumu modeļa — lokāluma, atkārtošanās, secības un īslaicīgo pīķu klātbūtnes.
- Vienumu izmēri un iegūšanas izmaksas: ja vienumiem ir atšķirīgi izmēri, kešēšanas lēmumiem jāņem vērā izmērs (piem., evict/vs/keep, cost-aware caching). Tāpat saglabā priekšmetus, kuru iegūšana ir dārga (ilgs laiks vai CPU), pat ja tie tiek retāk pieprasīti.
- Derīguma termiņi (TTL): dažām kešatmiņām dati var kļūt novecojuši (piem., DNS, web, ziņu kešs). Tad papildus aizvietošanas algoritmam izmanto laika pārbaudes (expire), kas var samazināt nepieciešamību pēc sarežģītiem izmešanas mehānismiem.
- Hibrīdi un adaptīvi risinājumi: ARC, CAR, 2Q un MQ ir piemēri, kā adaptīvi apvienot priekšrocības no vairākām stratēģijām, lai panāktu stabilāku veiktspēju dažādās slodzēs.
- Trūkumi un iespējamie problēmjautājumi: LRU var cieš no kapacitātes triešanu (sequential scan), LFU — no ilgstošas populāritātes iestrēgšanas, tiešā kartēšana — no sadursmēm. Tāpat atmiņas kešos svarīga ir konkurences vadība un vienlaicīga piekļuve.
Kešatmiņas saskaņotība
Ja tajā pašā datus glabā vairāki neatkarīgi kešatmiņu slāņi vai serveri, jānodrošina datu kešatmiņas saskaņotība. Tas ir svarīgi vietās ar vairākiem datubāzes serveriem, starpniekserveriem vai sadalītām kešatmiņām — nepieciešami protokoli un politikas (invalidate, update, write-through, write-back), lai novērstu novecojušu vai nekonsekventu datu izmantošanu.
Kad izvēlēties kuru algoritmu?
- Ja darba slodze rāda spēcīgu lokālu atkārtošanos un ir nepieciešama stabilitāte — LRU vai tā uzlabojumi (2Q, LIRS).
- Ja nepieciešama zema metadatu izmaksu stratēģija (piem., CPU kešatmiņa) — PLRU, CLOCK vai divvirzienu asociatīvais komplekts.
- Ja dati mēdz būt ilgi populāri — LFU ar nolietojumu vai ARC.
- Ja slodze mainās dinamiskāk — adaptīvie algoritmi (ARC, CAR, MQ) parasti sniedz vispār labākus rezultātus.
Secinājums: kešatmiņas aizvietošanas algoritmu izvēle ir kompromiss starp trāpījumu skaitu, latenci, metadatu izmaksām un darba slodzes īpašībām. Praktiskā izvēlē bieži tiek lietoti hibrīdi un aproksimējoši risinājumi, jo tie nodrošina labāku sniegumu reālās sistēmās nekā tīri teorētiski optimālie, bet neimplementējami risinājumi.

Jautājumi un atbildes
J: Kas ir kešatmiņas algoritms?
A: Kešatmiņas algoritms ir algoritms, ko izmanto kešatmiņas vai datu grupas pārvaldībai. Tas izlemj, kurš vienums jāizdzēš no kešatmiņas, kad tā ir pilna.
J: Kas ir trāpījuma rādītājs?
A: Hit rate raksturo, cik bieži pieprasījums var tikt izpildīts no kešatmiņas.
J: Ko raksturo latence?
A: Latence raksturo, cik ilgi var saņemt kešatmiņā esošo elementu.
J: Kas ir Beladija optimālais algoritms?
A: Beladija optimālais algoritms, ko dēvē arī par gaišreģa algoritmu, ir efektīvs kešatmiņas algoritms, kas vienmēr izmet informāciju, kura nebūs vajadzīga visilgākā laika posmā nākotnē. Šo rezultātu parasti nav iespējams īstenot praksē, jo tam nepieciešams paredzēt, kas būs vajadzīgs tālā nākotnē.
J: Kā darbojas LRU (Least Recently Used)?
A: LRU vispirms dzēš vismazāk nesen izmantotos elementus, un tam ir jāseko līdzi tam, kas un kad tika izmantots, izmantojot "vecuma bitus" katrai kešatmiņas līnijai un izsekojot, kura no tām tika izmantota vismazāk nesen, pamatojoties uz vecuma bitiem. Katru reizi, kad tiek izmantota kešatmiņas līnija, attiecīgi tiek mainīts visu pārējo kešatmiņas līniju vecums.
J: Kā darbojas visnesenāk izmantotais (MRU)?
A: MRU vispirms izdzēš visnesenāk izmantotos vienumus, un šo kešēšanas mehānismu parasti izmanto datubāzu atmiņas kešatmiņā.
J: Kādi citi algoritmi pastāv, lai saglabātu kešatmiņas saskaņotību?
A; Pastāv dažādi algoritmi, lai saglabātu kešatmiņas saskaņotību, ja koplietojamiem datiem izmanto vairākas neatkarīgas kešatmiņas, piemēram, ja vairāki datubāzes serveri atjaunina vienu koplietojamu datu datni.
Saistītie raksti
Autors
AlegsaOnline.com Kešatmiņas aizvietošanas algoritmi: LRU, LFU, ARC un citi Leandro Alegsa
URL: https://lv.alegsaonline.com/art/15882
Avoti
- usenix.org : usenix.org/legacy/events/fast03/tech/full_papers/megiddo/megiddo.pdf
- usenix.org : usenix.org