Superskalārais procesors — definīcija, darbības princips un piemēri
Iepazīsties ar superskalāro procesoru: instrukciju līmeņa paralēlisms, dispečera darbība, dublētās ALU/FPU vienības un praktiski piemēri veiktspējas uzlabošanai.
Superskalārā CPU konstrukcija nodrošina paralēlo skaitļošanu, ko sauc par instrukciju līmeņa paralēlismu vienā CPU, kas ļauj veikt vairāk darba ar to pašu taktātrumu. Tas nozīmē, ka CPU izpilda vairāk nekā vienu instrukciju takts cikla laikā, izpildot vairākas instrukcijas vienlaicīgi (ko sauc par instrukciju dispečerizāciju) dublētās funkcionālajās vienībās. Katra funkcionālā vienība ir izpildes resurss procesora kodolā, piemēram, aritmētiskā loģiskā vienība (ALU), svārstīgā komata vienība (FPU), bitu pārveidotājs vai reizinātājs.
Attēlu galerija
2 Attēli
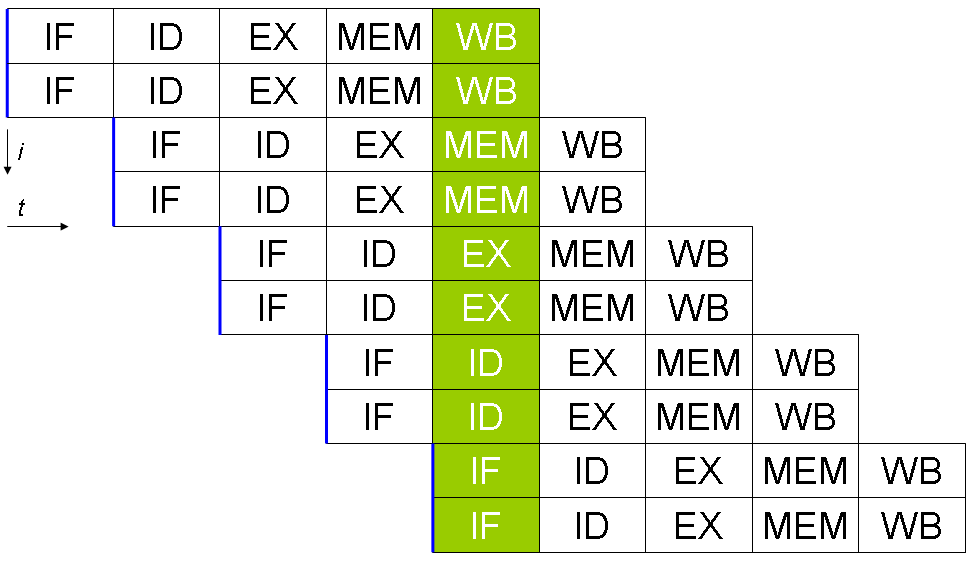
Darbības princips
Superskalāra procesora galvenā ideja ir ļaut aparatūrai vienlaikus izpildīt vairākas neatkarīgas instrukcijas, izmantojot vairākas paralēlas izpildes vienības. Tam nepieciešamas vairākas atbalstošas funkcijas procesora kodolā:
- Instrukcijas jābūt pieejamām no sakārtota instrukciju saraksta (fetch/decode posmi).
- Procesora aparatūra spēj noteikt datu atkarības starp instrukcijām, lai nepieļautu nekorektu izpildi.
- Jāspēj nolasīt (fetch) un dekodēt vairākas instrukcijas vienā takts ciklā, lai aizpildītu izpildes vienības.
Parasti superskalārs procesors darbojas kopā ar konveijeru (pipeline): instrukcijas tiek lasītas, dekodētas, izsniegtas (issue) uz izpildes vienībām, izpildītas un, ja nepieciešams, reģistrēt rezultāti (retire) secīgi. Superskalārā pieeja paplašina šo plūsmu, ļaujot vairākām instrukcijām atrasties dažādos posmos vienlaikus un vairākām instrukcijām tikt izpildītām vienlaicīgi.
Galvenie tehniskie risinājumi un mehānismi
- Datu atkarību noteikšana: aparatūra pārbauda, kuras instrukcijas izmanto vienādus reģistrus vai atmiņas adreses, lai nepieļautu konfliktus (RAW, WAR, WAW).
- Out-of-order izpilde: instrukcijas var tikt izpildītas ne secībā, ja nav datu atkarību, lai labāk izmantotu izpildes vienības. Rezultātu sakārtošanai tiek izmantotas struktūras kā reorder buffer (ROB).
- Register renaming: noņem mākslīgās atkarības (WAW, WAR), piešķirot fiziskus reģistrus loģisko reģistru vietā.
- Gadījumu (hazard) vadība: aparatūra atpazīst un apstrādā atkarības, zaru prognozēšana (branch prediction) samazina plūsmas pārtraukumus.
- Instrukciju dispečers (issue/dispatch unit): nolasa un sadala instrukcijas uz brīvām izpildes vienībām, mēģinot aizpildīt visu izpildes joslu (issue width).
Superskalārā vs vektoru un VLIW
Katra skalārā instrukcija apstrādā vienu vai dažus datu elementus, kamēr vektorprocesori (SIMD) apstrādā daudzus elementus ar vienu instrukciju. Superskalārais procesors apvieno skalāru instrukciju paralēlismu ar pieejamu vairākumu izpildes vienību, proti:
- Katra instrukcija apstrādā vienu datu elementu.
- Kodola iekšienē ir vairākas dublējošas funkcionālās vienības, tāpēc vairākas instrukcijas vienlaikus apstrādā neatkarīgus datu elementus.
Atšķirībā no VLIW (Very Long Instruction Word), kur kompilators atbild par paralelizācijas plānošanu, superskalāra aparatūra dinamiski atrod paralēlismu izpildes laikā.
Tipiskas arhitektūras īpašības un rādītāji
- Issue width (izsniegšanas platums): cik instrukcijas var tikt izsniegtas vienā takts ciklā — parasti no 2 līdz 8, pat vairāk īpašos serveru dizainos.
- IPC (instructions per cycle): reāls izpildīto instrukciju skaits uz vienu taktu; superskalārie dizaini mēģina palielināt IPC.
- Tipisks galddatoru/mobilo kodolu konfigurācijas piemērs: līdz 4 ALU, 2 FPU un divas SIMD vienības, kā minēts iepriekš.
Priekšrocības un trūkumi
- Priekšrocības: augstāks throughput, labāka resursu izmantošana, lielāks IPC bez nepieciešamības palielināt takts frekvenci.
- Trūkumi: ievērojama aparatūras sarežģītība (dispečeru loģika, reģistru pārdalīšana, ROB), lielāka enerģijas patēriņa un dizaina izmaksas; ierobežojumi, ko nosaka programmas sekvencialitāte un datu atkarības.
Praktiski risinājumi datu atkarību problēmu mazināšanai
Lai superskalārais procesors efektīvi izmantotu paralēlismu, tiek pielietoti šādi paņēmieni:
- Tomasulo algoritms un citi dinamiski plānošanas mehānismi — ļauj izpildīt instrukcijas atbilstoši resurss pieejamībai un atkarībām.
- Branch prediction — lai samazinātu konvejera skaitīšanas pārtraukumus pie nosacījumu zariem.
- Speculative execution — izpilde paredzētajās zara ceļos, rezultātu anulēšana, ja prognoze bija kļūdaina.
Konveijers un superskalārā attiecība
Lielākā daļa superskalāru procesoru ir arī konveijeru procesori — konveijers palielina takta frekvenci un iztukšo laika posmus, kamēr superskalārais izplata darbu starp vairākām vienībām. Tomēr iespējami arī superskalāri dizaini bez konveijera vai konveijeri bez superskalāra dispečera — tie funkcionē pēc līdzīga principa, bet atšķiras pēc tīmekļa un plūsmas organizācijas.
Piemēri un vēsture
No 2008. gada visi vispārējas nozīmes procesori prakses līmenī ir superskalāri. Vēsturiski nozīmīgi superskalāri piemēri ir Intel arhitektūras, piemēram, Pentium Pro (ieviests out-of-order un superskalāro elementu izmantošanu), arī vēlākas paaudzes kā Intel Core sērija. AMD arhitektūra (piem., Athlon, K8) arī izmanto superskalāras un out-of-order mehānismus. Mūsdienās daudzās mobilajās un iebūvētajās sistēmās esošās ARM bāzētās kodolu sērijas (piem., Cortex-A sērija) ir superskalāras, un arī daudzas Apple A sērijas sistēmas uz čipa (SoC) satur superskalārus elementus.
Dizaina apsvērumi
Superskalārā projektēšanā ir īpaši svarīgi uzlabot instrukciju dispečera precizitāti un nodrošināt, lai tas spētu aizņemt vairākas funkcionālās vienības ilgtspējīgi. Ja dispečers nespēj aizņemt visas vienības, procesora veiktspēja samazinās. Tāpēc liela daļa inženierijas tiek veltīta līdzekļiem, kas palielina instrukciju paralēlismu — labas zaru prognozes, efektīva register renaming, ROB un dinamiskā plānošana.
Kopsavilkums
Superskalārais procesors palielina skaitļošanas caurlaidību, izpildot vairākas instrukcijas vienlaicīgi, izmantojot dublētas izpildes vienības un sarežģītu dispečera loģiku. Tas bieži tiek kombinēts ar konveijeriem, out-of-order izpildi, reģistru pārdali un zaru prognozēšanu, lai maksimizētu IPC un samazinātu veiktspējas ierobežojumus, ko nosaka datu atkarības un zaru nosacījumi.


Ierobežojumi
Superscalar procesora konstrukcijas veiktspējas uzlabošanu ierobežo divas lietas:
- Instrukciju sarakstā iebūvētā paralēlisma līmenis
- Dispečera un datu atkarības pārbaudes sarežģītība un laika izmaksas.
Pat ja parastā superskalārajā CPU ir bezgalīgi ātra atkarību pārbaude, ja instrukciju sarakstā ir daudz atkarību, tas arī ierobežotu iespējamo veiktspējas uzlabošanos, tāpēc vēl viens ierobežojums ir kodā iebūvētā paralēlisma apjoms.
Neatkarīgi no dispečera ātruma ir praktiski ierobežots vienlaikus nosūtāmo instrukciju skaits. Lai gan aparatūras attīstība ļaus palielināt funkcionālo vienību skaitu (piemēram, ALU) katrā CPU kodolā, instrukciju atkarību pārbaudes problēma palielinās līdz tādai robežai, ka sasniedzamā superskalārās dispečerēšanas robeža ir nedaudz maza. -- visticamāk, piecas līdz sešas vienlaicīgi dispečējamas instrukcijas.
Alternatīvas
- Vienlaicīga daudzpavedienu apstrāde (Simultaneous multithreading): bieži saīsināti saukta par SMT, ir metode, ar ko uzlabo superskalāro procesoru kopējo ātrumu. SMT ļauj vairākiem neatkarīgiem izpildes pavedieniem labāk izmantot resursus, kas pieejami modernajā superskalārajā procesorā.
- Daudzkodolu procesori: superskalārie procesori atšķiras no daudzkodolu procesoriem ar to, ka vairākas dublētās funkcionālās vienības nav veseli procesori. Viens superskalārais procesors sastāv no modernām funkcionālajām vienībām, piemēram, ALU, veselu skaitļu reizinātāja, veselu skaitļu pārveidotāja, svārstīgā komata vienības (FPU) u. c. Katrai funkcionālajai vienībai var būt vairākas versijas, lai varētu paralēli izpildīt daudzas instrukcijas. Tas atšķiras no daudzkodolu procesoriem, kas vienlaicīgi apstrādā instrukcijas no vairākiem pavedieniem, pa vienam pavedienam katrā kodolā.
- Cauruļveida procesori: superskalārie procesori arī atšķiras no cauruļveida procesora, kurā vairākas instrukcijas var vienlaicīgi atrasties dažādās izpildes stadijās.
Dažādās alternatīvās metodes nav savstarpēji izslēdzošas - tās var apvienot (un bieži vien arī apvieno) vienā procesorā, tāpēc ir iespējams izstrādāt daudzkodolu procesoru, kurā katrs kodols ir neatkarīgs procesors ar vairākiem paralēliem superskalāriem cauruļvadiem. Daži daudzkodolu procesori ietver arī vektoru iespējas.
Saistītās lapas
- Paralēlā skaitļošana
- Instrukciju līmeņa paralēlisms
- Vienlaicīga daudzvirzienu lasīšana (SMT)
- Daudzkodolu procesori
Jautājumi un atbildes
J: Kas ir superskalārā tehnoloģija?
A: Superskalārā tehnoloģija ir paralēlās skaitļošanas pamatveids, kas ļauj apstrādāt vairāk nekā vienu instrukciju katrā takts ciklā, izmantojot vairākas izpildes vienības vienlaicīgi.
J: Kā darbojas superskalārā tehnoloģija?
A.: Superskalārā tehnoloģija paredz, ka instrukcijas tiek ievadītas procesorā secīgi, tā darbības laikā tiek meklētas datu atkarības un katrā takts ciklā tiek ielādēta vairāk nekā viena instrukcija.
J: Kāda ir atšķirība starp skalārajiem un vektoru procesoriem?
A: Skalārajā procesorā instrukcijas parasti strādā ar vienu vai diviem datu elementiem vienlaikus, bet vektoru procesorā instrukcijas parasti strādā ar daudziem datu elementiem vienlaikus. Superskalārais procesors ir abu veidu kombinācija, jo katra instrukcija apstrādā vienu datu elementu, bet vienlaikus tiek izpildītas vairākas instrukcijas, tāpēc procesors vienlaikus apstrādā daudz datu elementu.
J: Kāda loma superskalārajā procesorā ir precīzam instrukciju dispečeram?
A: Precīzs instrukciju dispečers ir ļoti svarīgs superskalārajam procesoram, jo tas nodrošina, ka izpildes vienības vienmēr ir aizņemtas ar darbu, kas, iespējams, būs nepieciešams. Ja instrukciju dispečers nav precīzs, tad daļu darba var nākties izmest, un līdz ar to procesors nebūs ātrāks par skalu procesoru.
Jautājums: Kurā gadā visi parastie procesori kļuva par superskalārajiem?
A: 2008. gadā visi parastie procesori kļuva par superskalārajiem.
Jautājums: Cik daudz ALU, FPU un SIMD vienību var būt parastā CPU?
A: Parastā CPU var būt līdz 4 ALU, 2 FPU un 2 SIMD blokiem.
Saistītie raksti
Autors
AlegsaOnline.com Superskalārais procesors — definīcija, darbības princips un piemēri Leandro Alegsa
URL: https://lv.alegsaonline.com/art/95080