Zipfa likums — definīcija, piemēri un pielietojumi
Zipfa likums — saprotama definīcija, skaidri piemēri un praktiski pielietojumi valodā, ekonomikā un datu analīzē. Uzzini, kāpēc šis empīriskais likums darbojas.
Zipfa likums ir empīrisks likums, kas formulēts, izmantojot matemātisko statistiku, un nosaukts lingvista Džordža Kingslija Zipfa vārdā, kurš pirmais to ierosināja. Kopš tā laika likums ir atklāts ne tikai valodas korpusos, bet arī daudzās citās sistēmās, kurās objekti tiek sakārtoti pēc biežuma vai izmēra.
Attēlu galerija
3 Attēli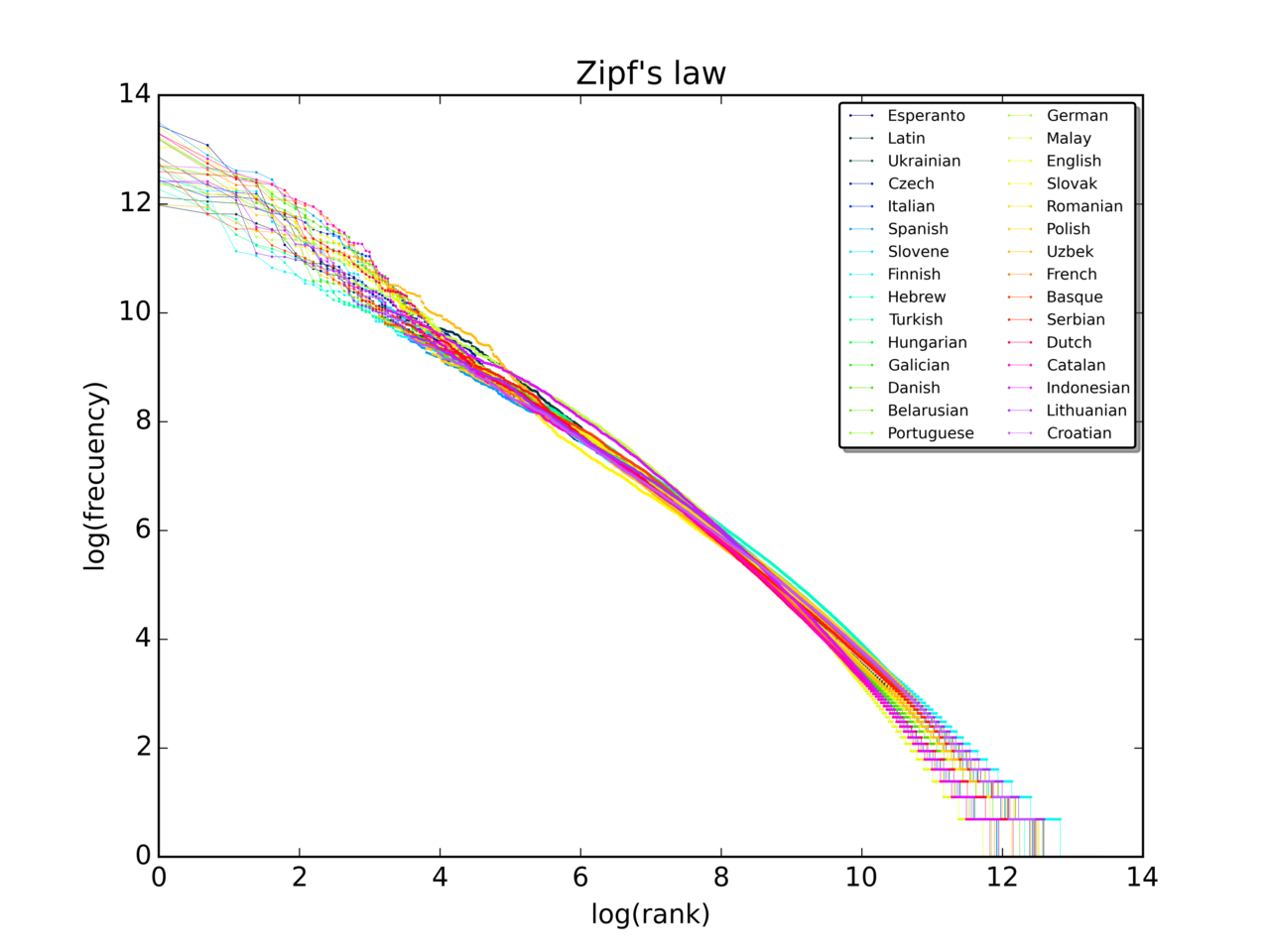


Matemātiskā forma
Standarta formulējums saka, ka vārda biežums f(r) ir apgriezti proporcionāls tā rangam r biežumu tabulā:
f(r) ∝ 1 / r^s, kur parasti s ≈ 1.
Tādējādi speciālā gadījumā, ja s = 1, f(r) ≈ C / r, kur C ir normalizācijas konstante, kas nodrošina, ka kopējā biežumu summa atbilst vienībai (vai kopējam vārdu skaitam). Par teorētisku bezgalīgu sarakstu C var izteikt ar Rīmana dzeta funkciju; praktiskā lietošanā, kad tiek analizēta ierobežota kopa, lieto atbilstošu normalizāciju (harmonisko summu).
Piemēri
Zipfa likums paredz, ka visbiežāk sastopamais vārds parādīsies aptuveni divreiz biežāk nekā otrais, trīs reizes biežāk nekā trešais utt. Piemēram, vienā angļu valodas vārdu izlasē visbiežāk sastopamais vārds "the" veido gandrīz 7 % no visiem vārdiem (69 971 no nedaudz vairāk nekā 1 miljona). Atbilstoši Zipfa likumam otrajā vietā ir vārds "of", kas veido nedaudz vairāk nekā 3,5 % vārdu (36 411 atkārtojumu), kam seko vārds "and" (28 852). Tikai aptuveni 135 vārdi ir nepieciešami, lai veidotu pusi no lielajā izlasē iekļautajiem vārdiem.
Šāda sakarība nav ierobežota tikai ar valodu. Līdzīga hierarhiska, traucējoša skaitļu sadalījuma forma parādās, piemēram, pilsētu iedzīvotāju skaitā, uzņēmumu izmēros, tīmekļa lapu apmeklētībā, grāmatu pārdošanā u. c. Pilsētu izmēru reitingu līdzīgu attiecību parādīšanos pirmoreiz pamanīja Felikss Auerbahs 1913. gadā.
Pielietojumi
- Valodas tehnoloģijas un NLP: Zipfa likums ietekmē valodas modeļu būvi, stopvārdu noteikšanu un vārdnīcu veidošanu; biežākie vārdi ir svarīgi statistiskajai valodas apstrādei.
- Datu kompresija: zinot, ka daži simboli vai vārdi parādās daudz biežāk, kompresijas algoritmi (piem., Huffmana kodēšana) var efektīvāk piešķirt īsākus kodus biežākajiem elementiem.
- Informācijas meklēšana: terminu svarīguma noteikšanā izmanto pretēju attieksmi pret biežumu (tf–idf) — ļoti bieži vārdi mazina atšķirīgumu starp dokumentiem.
- Ekonomika un sociālās zinātnes: modelē uzņēmumu lielumu, ienākumu sadalījumu vai bagātības koncentrāciju, kur bieži parādās Power law tipa sadalījumi.
- Kartogrāfija un pilsētplānošana: Zipfa līdzīgi modeļi palīdz prognozēt pilsētu sistēmu struktūru un centrālās vietas hierarhiju.
Paplašinājumi, teorijas un iespējamie cēloņi
Ir vairāki veidi, kā vispārināt vai izskaidrot Zipfa novērojumu:
- Zipf–Mandelbrota likums: ņem vērā nobīdi ranga galvā, raksturojot biežumu kā f(r) ∝ 1/(r+q)^s, kur q ir nobīdes parametrs.
- Pārmērīga pieaugšana (preferential attachment): mehānisms, kur jaunām vienībām ir lielāka varbūtība pievienoties jau lielām/ populārām vienībām (“bagātie kļūst bagātāki”), rada power-law sadalījumus.
- Zipfa princips — "mazākā pūle": Zipf pats ieteica, ka valoda un cilvēku darbība resultē no kompromisa starp runātāja un klausītāja pūlēm, radot īpašu optimizācijas stāvokli.
- Stohastiskie modeļi un nejaušā tipa (random text) skaidrojumi: dažas vienkāršas nejaušas ģenerēšanas stratēģijas var dot līdziniekus Zipfa tipa biežumiem, tomēr šie skaidrojumi bieži neatbilst reālajai vārdu semantikā/struktūrā.
Tomēr nav viennozīmīgas vienošanās, un visticamāk ir vairāku mehānismu kopums, kas rada līdzīgu empīrisku iznākumu daudzos kontekstos.
Testēšana un ierobežojumi
Uz Zipfa likuma pārbaudi var ietekmēt daudzi faktori:
- Paraugu lielums: mazi korpusi var radīt izliekumus un nestabilitāti rangu īpašībās.
- Tokenizācija un lematizācija: kā tiek skaitīti vārdi (piem., locījumi, salikteņi) maina biežumu sarakstu.
- Log–log attēlojums un regresijas pieeja: lineāra regresija uz log–log datiem bieži tiek lietota, taču tā var būt maldinoša; precīzāka ir maksimuma ticamības (MLE) metožu izmantošana un derīguma pārbaude (goodness-of-fit).
- Aizmugures un astes daļas novirzes: ļoti reti vai ļoti bieži elementi var neatbilst vienkāršam 1/r modelim; parasti novērojama dažādu slīpumu daļa ranga galvā un astē.
Saistītie koncepti
- Heaps likums: raksturo jaunu vārdu skaita pieaugumu korpusā — vārdu krājuma izmērs retos gadījumos aug proporcionāli tekstu skaitam (V(N) ∝ N^β), un tas ir savienojams ar Zipfa parādību.
- Pareto sadalījums: Zipfa likums valodas rangos ir cieši saistīts ar Pareto un citiem power-law sadalījumiem, kas apraksta "garās astes" fenomenu.
Secinājums
Zipfa likums ir viena no spēcīgākajām empīriskajām novērošanām gan lingvistikā, gan plašākā kompleksu sistēmu pētījumā. Lai gan vienkāršākā forma f(r) ∝ 1/r ir noderīga aptuvenai izpratnei un daudzos praktiskos pielietojumos, reālos datos parasti novēro nobīdes un izmaiņas, kuras prasa precīzākus modeļus un rūpīgu statistisku pārbaudi. Nav pilnīgi skaidrs, kāpēc Zipfa likums ir tik vispārējs, taču tas, visticamāk, rodas no kombinācijas strukturālu ierobežojumu, optimizācijas principu un stohastisku procesu darbības.
Jautājumi un atbildes
J: Kas ir Zipfa likums?
A: Zipfa likums ir empīriskais likums, kas nosaka, ka vārda biežums lielā izlasē ir apgriezti proporcionāls tā rangam biežumu tabulā.
J: Kas ierosināja Zipfa likumu?
A: Zipfa likumu pirmais ierosināja lingvists Džordžs Kingslijs Zipfs.
J: Kā Zipfa likums izskaidro vārdu biežumu angļu valodas vārdu izlasē?
A: Saskaņā ar Zipfa likumu angļu valodas vārdu izlasē visbiežāk sastopamais vārds ir apmēram divreiz biežāk nekā otrais biežāk sastopamais vārds, trīs reizes biežāk nekā trešais biežāk sastopamais vārds utt. Šī tendence turpinās, samazinoties vārda rangam.
J: Kādu procentu no visiem vārdiem vienā angļu valodas vārdu izlasē veido visbiežāk sastopamais vārds?
A: Vienā angļu valodas vārdu izlasē visbiežāk sastopamais vārds ("the") veido gandrīz 7 % no visiem vārdiem.
J: Kāda ir sakarība starp vārdu skaitu, kas nepieciešams, lai veidotu pusi no parauga, un šo vārdu biežumu?
Atbilstoši Zipfa likumam ir vajadzīgi tikai aptuveni 135 vārdi, lai aptvertu pusi no liela parauga vārdiem.
J: Kādiem citiem reitingiem piemīt Zipfa likums?
A: Tāda pati sakarība, ko Zipfa likums apraksta vārdu biežumam, parādās arī citos ar valodu nesaistītos reitingos, piemēram, dažādu valstu pilsētu iedzīvotāju rangā, korporāciju lieluma un ienākumu rangā.
J: Kas pamanīja, ka pilsētu rangos pēc iedzīvotāju skaita parādās sadalījums?
A: Sadalījuma parādīšanos pilsētu reitingos pēc iedzīvotāju skaita pirmais pamanīja Felikss Auerbahs 1913. gadā.
Saistītie raksti
Autors
AlegsaOnline.com Zipfa likums — definīcija, piemēri un pielietojumi Leandro Alegsa
URL: https://lv.alegsaonline.com/art/110649
Avoti
- books.google.com : P. 139