Cilvēka genoms: DNS, hromosomas un HGP atklājumi
Aizraujošs pārskats par cilvēka genomu — DNS, hromosomu struktūru un Cilvēka genoma projekta (HGP) atklājumiem, sekvencēm un ENCODE pētījumu nozīmi medicīnā.
Cilvēka genoms glabājas 23 hromosomu pāros šūnas kodolā un mazajā mitohondriālajā DNS. Cilvēka haploīdais genoms satur aptuveni 3,2 miljardus bāzes pāru, bet diploīda šūna – divkāršo šo daudzumu. Mitochondriālā DNS ir neliela, apmēram 16 569 bāzu gari cirkulāri ķēde, kas pārmantojas galvenokārt no mātes. Tagad par DNS sekvencēm, kas atrodas mūsu hromosomās, ir zināms daudz vairāk nekā pirms gadiem, taču daudz kas joprojām ir jāpēta. Daļēji ir zināms, ko DNS patiesībā dara — zinām, kur atrodas olbaltumvielu kodējošie gēni (apmēram 20 000–21 000), bet lielā daļa genoma satur ne-kodējošas zonas, atkārtotus elementus un regulējošas secības, kuru funkcijas ietver gēnu izteiksmes kontroli, strukturālās lomas u.c. Šo zināšanu izmantošana medicīnā un biotehnoloģijā tikai sākusies, un tās attīstība turpinās strauji.
Attēlu galerija
5 Attēli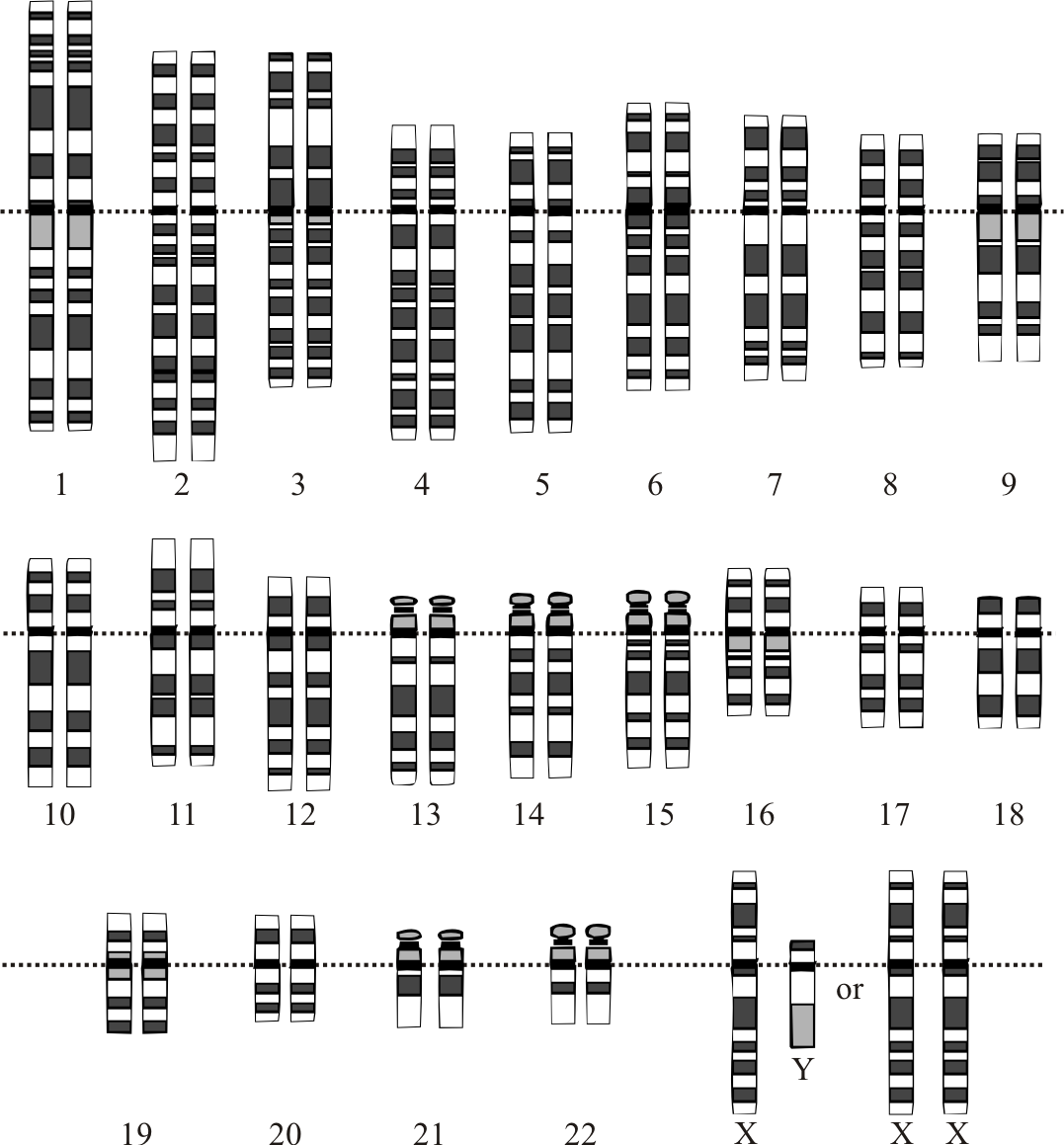


Kas ir svarīgi zināt par cilvēka genomu
- Olbaltumvielu kodējošie gēni: aptuveni 20–21 tūkstotis; tie veido nelielu daļu no kopējā genoma.
- Ne-kodējošais DNS: daudzviet satur regulējošas sekvences (promotorus, enhancerus), nelielas kodēšanas vienības (miRNA, lncRNA) un atkārtotus elementus (transpozonus, satelītsekvences).
- Reprodukcijas un evolūcijas aspekts: ģenētiskās variācijas — SNP, insercijas/delēcijas, strukturālas variācijas — ietekmē veselību un fenotipus.
- Epigenētika: DNS metilācija un histonu modifikācijas regulē gēnu ekspresiju neatkarīgi no DNA sekvences.
Cilvēka genoma projekta (HGP) ietvaros tika izveidota references secība, ko visā pasaulē izmanto bioloģijā un medicīnā. Nature publicēja valsts finansētā projekta ziņojumu, bet Science publicēja Celera darbu. Šajos dokumentos aprakstīja, kā tika iegūta sākotnējā sekvences karte, un sniedza pirmos analītiskos rezultātus. Pirmie projekta rezultāti tika publicēti 2001. gadā (skeleta veidā), bet turpmākajos gados turpināja uzlabot montāžas, kļūdu labošanas un nepāra/atkārtoto reģionu kartēšanas metodes. Uzlabotie projekti un papildus montāžas tika publicēti 2003. un vēlākajos gados, aizpildot lielu daļu sākotnējo “caurumu” — kopumā agrākā references secība aptvēra lielāko daļu genoma, tomēr daži sarežģītie reģioni (piemēram, centromēras, garas satelītsekvences un daži telomēru posmi) bija nepilnīgi.
ENCODE un funkciju karte
Jaunākajā un plašākajā pieejā, ENCODE (ENCyclopedia Of DNA Elements), tiek pētīts, kā tiek kontrolēti gēni un kādas funkcijas pilda ne-kodējošie genoma reģioni. ENCODE mērķis ir identificēt DNS reģionus, kas iesaistīti transkripcijas regulācijā, hromatīna organizācijā, transkripcijas faktoru sasaistē un citu molekulāro procesu vadībā. Projektā tiek izmantotas dažādas metodes: transkriptoma analīze (RNA-seq), transkripcijas faktoru sasaiste (ChIP-seq), atvērtā hromatīna kartēšana (ATAC-seq, DNase-seq), epigenētiskās modifikācijas un funkcionālie testi.
Praktiskā nozīme un izaicinājumi
- Medicīna: genoma dati palīdz identificēt slimību ģenētiskos cēloņus, izstrādāt precīzas diagnostikas metodes, farmakogenomiku un personalizētu terapiju (piem., gēnu terapija, mērķterapijas vēža ārstēšanā).
- Pētījumu izaicinājumi: sarežģīti atkārtoti reģioni, struktūrvielu varianti un haplotipu fāzēšana joprojām rada tehniskas grūtības. Agrākā references secība bija ierobežota ar dažiem nepilnīgiem reģioniem, taču pēdējos gados starptautiskas iniciatīvas (piem., Telomere-to-Telomere un Human Pangenome Reference Consortium) strādā, lai izveidotu pilnīgākas un daudzveidīgākas references.
- Paveiktie uzlabojumi: jaunākas references montāžas (piem., GRCh sērija) un T2T projekts ir aizpildījuši daļu iepriekšējo “caurumu”, uzlabojot mūsu izpratni par centromērām, telomēriem un citiem sarežģītiem reģioniem.
- Sabiedrības un ētikas jautājumi: ģenētiskās informācijas privātums, datu drošība, diskriminācijas risks un informēta piekrišana ir būtiski aspekti, kurus regulē gan likumi, gan profesionālās vadlīnijas.
Nākotnes virzieni
Turpmākajās gadu desmitgadēs gaidāma genoma pētījumu paplašināšanās uz populāciju līmeņa daudzveidību (lai references nebūtu biasētas uz vienu populāciju), pilnīgāku strukturālo variantu kartēšanu, integrāciju ar epigenētikas un vienšūnu līmeņa datiem, kā arī plašāka izmantošana medicīnā. Arī tehnoloģiju progress — ilgās secvenču metodes, precīza montāža un mākslīgais intelekts analīzē — turpinās mainīt mūsu izpratni par to, kā DNS nosaka cilvēka bioloģiju un veselību.

DNS un olbaltumvielas
Cilvēka genoms satur nedaudz vairāk nekā 20 000 olbaltumvielas kodējošu gēnu, kas ir daudz mazāk, nekā tika gaidīts. Patiesībā tikai aptuveni 1,5 % genoma kodē olbaltumvielas, bet pārējo daļu veido nekodējošās RNS gēni, regulatīvās sekvences un introni.
Tomēr viens gēns, izmantojot RNS splicēšanu, var radīt dažādus proteīnus. Viens konkrēts Drosophila gēns (DSCAM) var tikt alternatīvi sašķelts 38 000 dažādās mRNS. Katra mRNS kodē atšķirīgu peptīdu ķēdi. Tāpēc saražoto olbaltumvielu skaits ievērojami pārsniedz kodējošo gēnu skaitu.
Ņemot vērā RNS sazarošanu un izmaiņas pēc RNS translācijas, kopējais unikālo cilvēka olbaltumvielu skaits var būt neliels miljons.
Doma, ka lielākā daļa DNS ir bezjēdzīgs "lūžņi", ir nepareiza. Vismaz 80 % genoma ir noteiktas funkcijas.
Atšķirības starp cilvēkiem un šimpanzēm
Šimpanze ir dzīvs dzīvnieks, kas šobrīd ir vistuvāk cilvēkam. 98,4 % cilvēku un šimpanžu DNS ir vienāda. Tomēr tas attiecas tikai uz vienu nukleotīdu polimorfismiem, proti, izmaiņām tikai atsevišķos bāzes pāros. Pilna aina ir diezgan atšķirīga.
2005. gadā tika publicēts parastās šimpanzes genoma secības projekts. Tas parādīja, ka reģioni, kas ir pietiekami līdzīgi, lai tos varētu pielīdzināt viens otram, veido 2400 miljonus no cilvēka genoma 3164,7 miljoniem bāzu, t. i., 75,8 % genoma.
Šie 75,8 % cilvēka genoma atšķiras no šimpanzes genoma par 1,23 %, jo tajā ir viennukleotīdu polimorfismu (SNP - atsevišķu DNS "burtu" izmaiņas genomā). Cita veida atšķirības, ko sauc par "indeliem" (iestarpinājumi/izdalījumi), veido vēl ~ 3 % atšķirību starp pielīdzināmajām sekvencēm. Turklāt vēl 2,7 % atšķirību starp abām sugām rada līdzīgu DNS sekvenču lielu segmentu (> 20 kb) kopiju skaita atšķirības. Tādējādi kopējā genomu līdzība varētu būt tikai aptuveni 70 %.
Saistītās lapas
Jautājumi un atbildes
Jautājums: Kur tiek glabāts cilvēka genoms?
A: Cilvēka genoms glabājas 23 hromosomu pāros šūnas kodolā un mazajā mitohondriālajā DNS.
J: Kas tagad ir zināms par mūsu hromosomu DNS sekvencēm?
A.: Tagad par mūsu hromosomu DNS sekvencēm ir zināms ļoti daudz.
J: Kas ir cilvēka genoma projekts?
A: Cilvēka genoma projekts (HGP) ir projekts, kura laikā tika izveidota cilvēka genoma atsauces secība.
J: Kāds ir sekvences procentuālais daudzums, kas ir aizpildīts saskaņā ar uzlabotajiem projektiem?
A.: Uzlabotie projekti, par kuriem tika paziņots 2003. un 2005. gadā, aizpildīja ≈92 % secības.
J: Kāds ir jaunākais projekts, kas pēta, kā tiek kontrolēti gēni?
A.: Jaunākais projekts ENCODE pēta gēnu kontroles veidu.
J: Lai gan cilvēka genoma secība ir pilnībā noteikta, vai tā ir pilnībā izprasta?
A.: Nē, cilvēka genoma secība vēl nav pilnībā izprasta.
J: Ko genomā dara nekodējošā DNS?
A: Nekodējošā DNS genomā veic svarīgas funkcijas, piemēram, regulē gēnu ekspresiju, hromosomu organizāciju un signālus, kas kontrolē epigenētisko pārmantojamību.
Saistītie raksti
Autors
AlegsaOnline.com Cilvēka genoms: DNS, hromosomas un HGP atklājumi Leandro Alegsa
URL: https://lv.alegsaonline.com/art/45651
Avoti
- nature.com : "Initial sequencing and analysis of the human genome"
- doi.org : 10.1038/35057062
- pubmed.ncbi.nlm.nih.gov : 11237011
- sciencemag.org : "The sequence of the human genome"
- ui.adsabs.harvard.edu : 2001Sci...291.1304V
- doi.org : 10.1126/science.1058040
- pubmed.ncbi.nlm.nih.gov : 11181995
- nature.com : nature.com/articles/489046a?error=cookies_not_supported&code=d4894f7c-6c0e-44a7-aa48-3d32…
- bbc.co.uk : bbc.co.uk/news/health-19202141
- ui.adsabs.harvard.edu : 2004Natur.431..931H
- doi.org : 10.1038/nature03001
- pubmed.ncbi.nlm.nih.gov : 15496913
- nature.com : nature.com/articles/nature03001?error=cookies_not_supported&code=20c2dd82-9871-4421-b41a-…
- doi.org : 10.1126/science.337.6099.1159